:format(webp))
tRPC explained: when to use it, when to keep REST, and what teams should plan for
Read this and you’ll leave with a clear sense of what tRPC does, how it changes the way frontend and backend work together, where it gives you genuine advantages, and the operational and organizational trade-offs to plan for.
What tRPC is and the core promise
tRPC is a TypeScript-first framework that lets you build end-to-end typed APIs without generating schemas or a separate client library. Instead of describing endpoints in OpenAPI/GraphQL and writing client code from that schema, you define routers and procedures in TypeScript and consume them directly from TypeScript clients, preserving types across the wire. For details and examples, see the tRPC documentation: Why tRPC .
The main user-facing benefits often cited are:
End-to-end type safety: your client sees the exact response shapes the server returns, compiled by TypeScript rather than runtime checks.
Minimal runtime and no code generation: tRPC avoids a separate schema language or heavy runtime layers that some frameworks use.
Excellent developer experience (DX) for TypeScript projects: tighter feedback loops and less boilerplate, as explored in this Prisma blog post on tRPC .
Feature | tRPC | REST | GraphQL |
|---|---|---|---|
End-to-end Type Safety | Full | Manual/schema | Partial |
Runtime & Code Generation | None/minimal | Depends | Schema-driven |
Developer Experience | High | Moderate | Good |
How tRPC works in practice
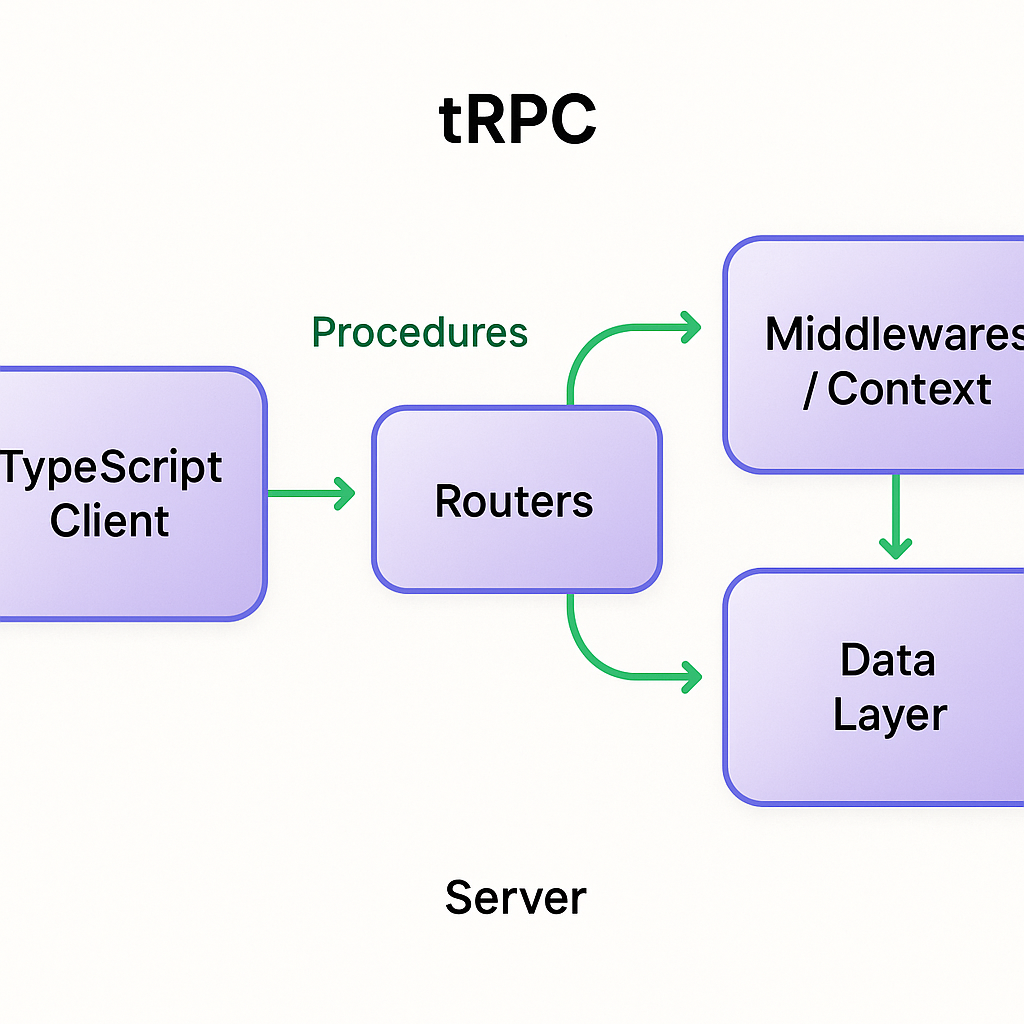
At its core, tRPC exposes routers composed of procedures. Each procedure is a handler with a typed input and output; the client uses generated type-safe callers or a light client wrapper to call those procedures directly.
Router + procedures model: you define handlers server-side and import types client-side, or use the tRPC client helpers for a near-zero-boilerplate call surface.
Integrations: tRPC pairs commonly with ORMs like Prisma (for database access) and client data libraries like TanStack Query, enabling typed requests and client caching patterns. See the TanStack Query overview for how it supports caching, invalidation, and optimistic updates.
Where tRPC shines — typical use cases
tRPC is particularly strong when:
Your frontend and backend share a TypeScript codebase (monorepo or close coupling).
You want fast iteration on internal application APIs and fewer manual API contract discussions.
You value developer velocity and reduced boilerplate for form-driven or CRUD-heavy apps.
Multiple practical guides and comparisons highlight these advantages and trade-offs when comparing tRPC to REST or GraphQL.
When tRPC might not be the best fit
tRPC assumes TypeScript on both sides and does not produce a universal, language-agnostic API schema like OpenAPI. That matters when:
You need public, language-agnostic SDKs or partner/third-party integrations (OpenAPI/REST or GraphQL are better fits).
Your services live across many repos/languages and sharing types is impractical.
You want an off-the-shelf ecosystem of API gateways, contract-first tooling, or automatic API documentation baked off OpenAPI.
Practical migration: moving from REST to tRPC (high level)
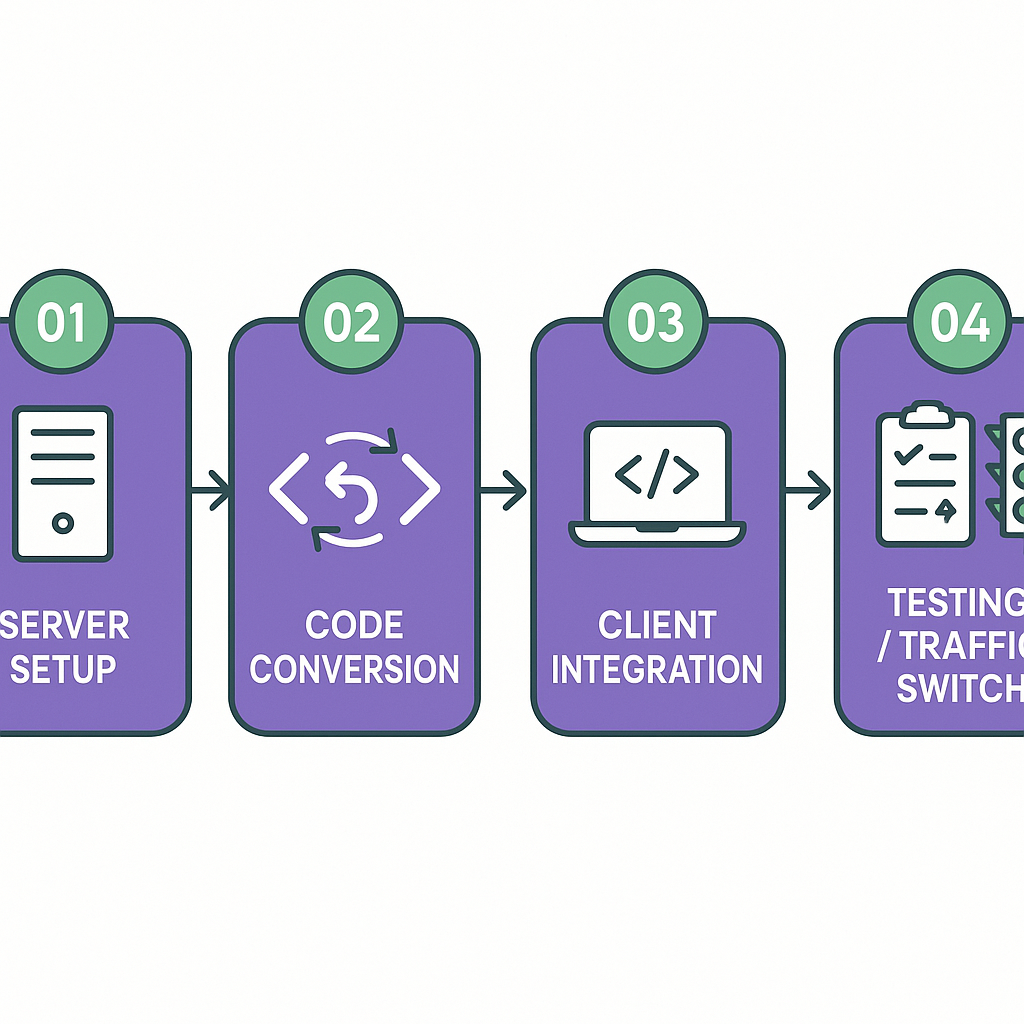
If you’re migrating an internal app-facing API, common steps include:
Set up a tRPC server and client integration in a feature branch.
Convert endpoints to procedures, preserving input validation and auth.
Update client calls to use tRPC callers or the React integration, keeping cache keys and optimistic-update logic intact.
Run integration tests and gradually switch traffic, keeping REST endpoints available for external clients until they migrate.
See a full migration walkthrough for more step-by-step guidance: Moving from REST to tRPC .
API evolution and versioning: a different mindset
One of the biggest shifts is how you handle API evolution:
REST commonly relies on explicit versioning and long-term backward compatibility for public APIs; there’s a large body of best practices for versioning REST APIs, such as Microsoft’s guidance on API design and versioning .
With tRPC’s tight TypeScript coupling, internal APIs can evolve continuously without producing a separate, long-lived versioned contract. That lets teams iterate faster on internal features but increases the need for coordinated releases or consumer testing when you change types.
How tRPC changes team structure and collaboration
Because tRPC creates a shared, typed surface between frontend and backend, it tends to blur the historical frontend/backend divide:
Teams can form around vertical features (feature teams) that own both the UI and the tRPC procedures powering it, reducing handoffs and the number of API design meetings. See the Atlassian playbook on feature teams for more on this pattern.
You’ll likely see fewer “API contract negotiation” cycles and more rapid end-to-end iteration, but product teams must adopt practices for coordination when multiple teams touch the same router or domain.
Operational and observability implications
tRPC changes some operational patterns you may be used to:
Traces and logs become procedure-centric rather than generic URL-route-centric. tRPC supports middlewares and context, which you can use to attach richer typed information to logs and traces.
You can integrate OpenTelemetry or other tracing libraries in those middlewares to produce spans for individual procedure calls—see the OpenTelemetry documentation for setup and best practices.
However, you should explicitly design your logging and metrics to preserve useful surface area (procedure name, caller info, input shapes where safe, and status), or you risk opaque monitoring similar to any RPC system.
API surface area and security posture
tRPC’s default model reduces accidental public exposure because there isn’t a separate, public OpenAPI document floating around. At the same time:
You must treat each procedure as a security boundary: implement authorization and validation at the procedure or middleware level rather than relying on coarse route guards.
For external/partner APIs you should still publish an explicit public layer (OpenAPI/REST/GraphQL) and only expose the procedures you intend to share.
Refer to general API security guidance, including the OWASP API Security Top 10 , when modeling your authentication and authorization.
Hybrid architectures: when to run both tRPC and REST/OpenAPI
Many teams adopt a hybrid pattern:
Use tRPC for internal, app-facing calls where TypeScript sharing and fast iteration matter.
Keep REST/OpenAPI (or GraphQL) for public, third-party, or multi-language clients that require stable, language-agnostic contracts and SDK generation. See the OpenAPI specification for details on schema design.
Use Case | Recommended API Approach | Notes |
|---|---|---|
Internal app-facing calls | tRPC | Fast iteration & TypeScript sharing |
Public or partner integrations | REST/OpenAPI | Stable, multi-language SDKs |
Mixed environments | Hybrid | Leverage both approaches as needed |
This split gives you the developer velocity of tRPC inside your app while maintaining long-term interoperability for external consumers.
Runtime performance trade-offs at scale
tRPC often has a small runtime and limited overhead compared to some GraphQL setups, which yields good performance for typical app calls. But performance at scale depends on more than framework overhead:
Router composition and large type inference graphs can increase cold-start times in serverless environments if your server bundles grow large. Monitor cold-start impacts on your chosen hosting platform—see AWS’s guide to Lambda performance and optimization for best practices.
REST can sometimes outperform more feature-rich RPCs when simple HTTP caching, CDN edge caching, and stateless resource URLs are used heavily.
Measure and test in your environment; general statements about “faster” don’t always hold in high-concurrency or serverless cold-start-sensitive workloads.
Caching and client-side data patterns without GraphQL
You don’t need GraphQL to get sophisticated client-side behaviors:
tRPC combines well with TanStack Query to provide typed queries, optimistic updates, cache invalidation, and refetching strategies.
That combination supports normalized cache patterns and optimistic updates similar to GraphQL workflows, while keeping payloads simple JSON objects and avoiding schema federation complexity.
Monorepo vs polyrepo dynamics
tRPC is easiest to adopt in a monorepo where TypeScript types can be shared directly between server and client:
In monorepos the “no schema generation” model is a big win because both sides import the same types—see Martin Fowler’s discussion of monorepos vs multirepos trade-offs .
In polyrepo or multi-language environments, sharing types is harder, which often forces teams to maintain a second interface (OpenAPI or generated SDKs) or introduce codegen to bridge repos.
Long-term interoperability and tooling risk
tRPC’s convenience comes with a trade: you’re leaning on a TypeScript-first stack. That gives you great DX today but can make future migrations harder if you need to support many languages or integrate with off-the-shelf API gateways and contract-test ecosystems that expect OpenAPI.
Plan ahead:
Keep a small, explicit surface for third parties (OpenAPI).
Add CI checks that validate consumer contracts within your monorepo.
Consider lightweight SDK generation if cross-language support becomes necessary.
Domain modeling and documentation discipline
Because tRPC uses TypeScript types as the contract, it’s easy for domain models to drift undocumented:
Enforce documentation practices: add README pages per router, use typed comments or DocGen tools, and include example payloads in your tests.
If you need machine-readable schemas, export JSON Schema/OpenAPI from TypeScript types (using tools) or maintain a parallel schema for public APIs. The trade-off is extra maintenance but it preserves discoverability for newcomers and external consumers.
Putting it into practice: a decision checklist
If you’re still deciding, use this quick checklist:
Is your frontend and backend TypeScript and co-located (monorepo)? → tRPC is a strong candidate.
Do you need public, multi-language SDKs or partner integrations? → prefer OpenAPI/REST or add a public layer.
Do you require per-procedure observability and auth controls? → instrument tRPC middlewares and integrate OpenTelemetry.
Will multiple teams own overlapping APIs? → define ownership boundaries, CI consumer checks, and staging for breaking changes.
Final practical tip: start small. Convert an internal feature or two to tRPC, add procedure-level metrics and auth, and validate the team flow and observability before enlarging the surface.
If you want, I can make a short migration plan tailored to your repo layout (monorepo vs polyrepo), the number of clients, and your CI setup — tell me those details and I’ll draft a step-by-step roadmap.
:format(webp))
:format(webp))
:format(webp))