:format(webp))
AI agents: architecture, safety, and production-ready patterns
In this article, you’ll learn what modern AI agents are, how their core architecture fits together, and which engineering patterns you should use when you deploy them in real systems. I cover the basic building blocks (planner, memory, tools), design and safety essentials, and then dig into advanced topics that top-ranking articles often omit—permission hierarchies, hallucination detection, observability, multi‑agent coordination, failure-recovery patterns, token optimization, and reward modeling—with verified links to support each technical claim.
What an AI agent is (short and practical)
An AI agent is a software system that perceives its environment, makes autonomous decisions, and takes action to achieve specific goals. Recent advancements in the field have led to agents that commonly use large language models (LLMs) as the primary controller to plan actions and call external tools. These systems differ from standard chatbots by their ability to use reasoning to complete multi-step tasks without constant user prompting.
Core components you'll see in production
Most practical agent designs include three interacting parts: a planner/controller (often an LLM), a memory subsystem for context, and a tool layer that performs effects in the real world. This “observe → plan → act” loop is a standard architectural pattern across recent literature.
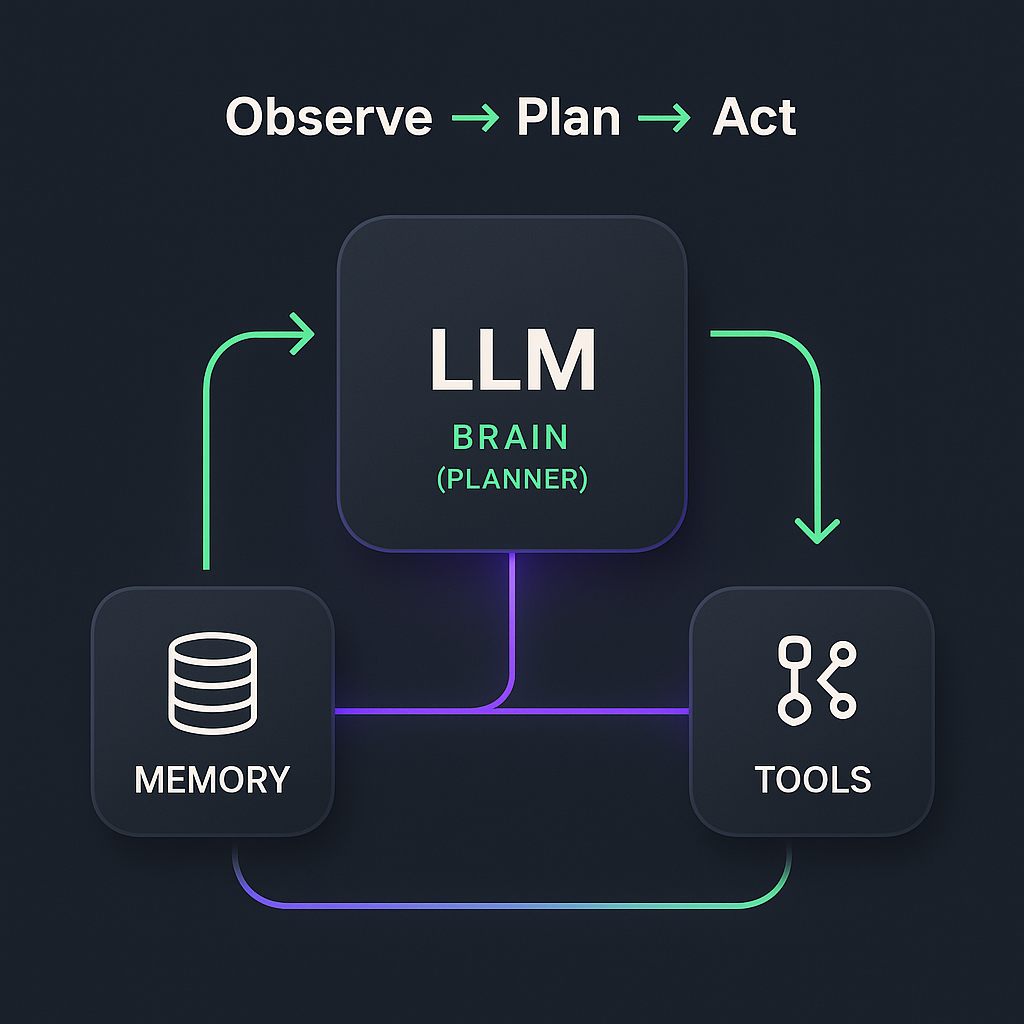
Planner / controller
The controller serves as the "brain" of the agent, generating complex plans, selecting the most appropriate tools for a task, and composing instructions based on the user's intent. LLMs are frequently utilized in this role because their flexible reasoning and language abilities allow them to parse ambiguous requests into structured action sequences.
Memory (short-term and long-term)
Agents combine short-term context, which lives within the LLM's finite context window, with long-term memory stores to maintain state across multiple interactions.
Tools and tool interfaces
Tools are the agent’s actuators—the mechanisms through which it interacts with the world, such as APIs, web browsers, databases, or code interpreters. To ensure reliability, developers must provide clear documentation on tool interfaces and capabilities , which allows the agent to understand precisely when and how to invoke a specific function to achieve the desired output.
Component | Primary Function | Example Implementation |
|---|---|---|
Planner/Controller | Reasoning & Logic | GPT-4o, Claude 3.5 |
Memory | State Retention | Pinecone, Redis, Context Window |
Tools | External Action | Search APIs, Python Interpreter, CRM Webhooks |
Designing agents: safety, constraints, and human oversight
Real-world deployments must enforce strict safety guardrails, ethical alignment, and human-in-the-loop control to reduce the risk of harmful outputs and satisfy organizational compliance requirements. Many organizations focus on implementing AI guardrails to enforce behavioral constraints and prevent agents from executing unauthorized or dangerous commands.
Human oversight and approval workflows are recommended for high-risk actions, particularly those involving financial transactions or sensitive data modifications.
Content moderation and access controls should be enforced at the tool and API layer rather than relying solely on the LLM’s internal alignment.
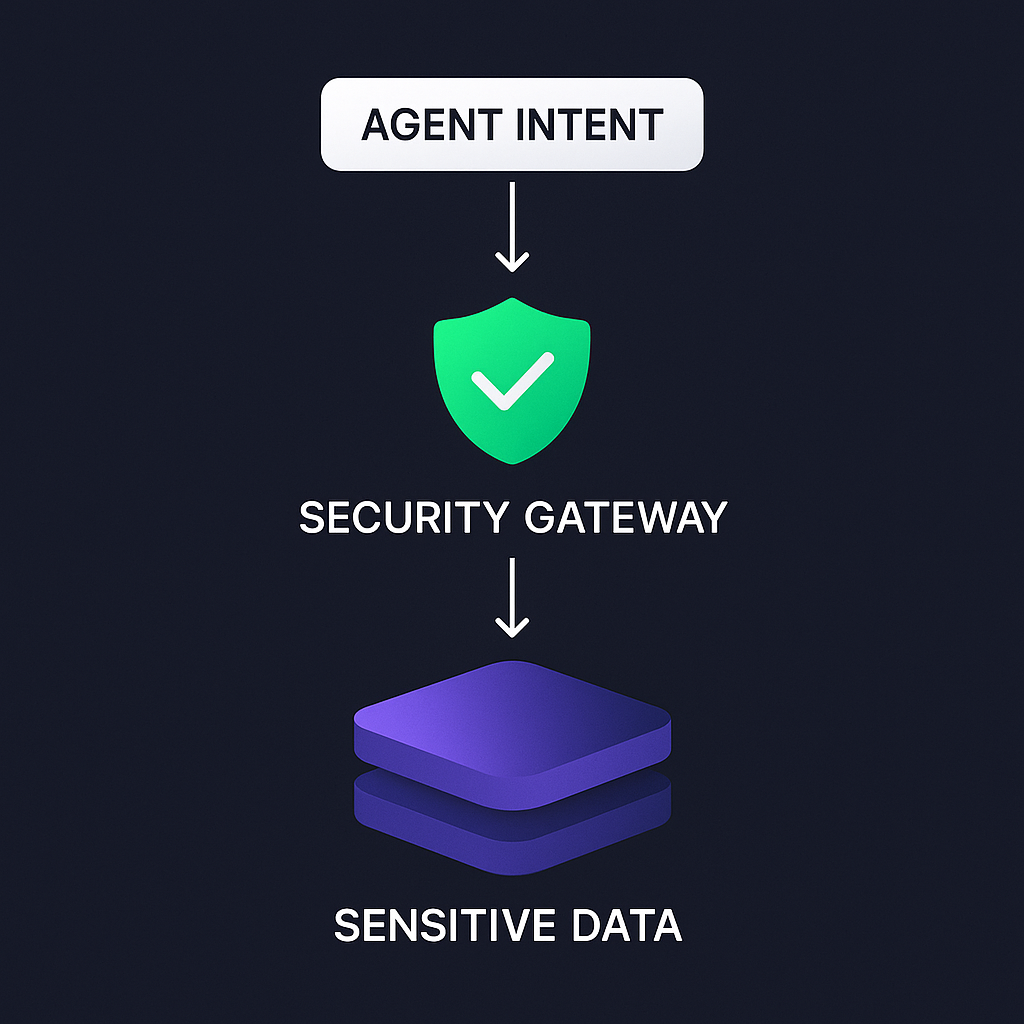
Permission hierarchies and role-based access control (RBAC)
When agents access sensitive systems or data, you need granular permission models so the agent can only perform actions permitted for the current user or role. The [National Institute of Standards and Technology (NIST) defines Role-Based Access Control (RBAC)](https://csrc.nist.gov/glossary/term/role-basedaccesscontrol) as a system where access rights are grouped by role name, which can significantly reduce the risk of unauthorized tool access and data leakage in multi-user agentic environments.
Practical tip: map agent “intents” to specific permissions and require a secondary authorization check before executing any tool call that modifies a system state.
Detecting and mitigating hallucinations in agent planning
Agents sometimes generate false facts or attempt to call tools that do not exist, a phenomenon known as "hallucination." You can reduce these errors by using Retrieval-Augmented Generation (RAG) to ground plans in verified sources , validating tool arguments with deterministic validators, and adding a verification step before final execution. By ensuring the agent bases its logic on retrieved facts rather than just its internal weights, the reliability of the output increases substantially.
Implement a “dry-run” or sandboxed simulation for risky tool calls so you can detect invalid or nonsensical actions before they affect live production systems.
Observability and interpretability frameworks for agents
For compliance and debugging, you need structured logs and explainability that show exactly why an agent chose each action. This involves recording the decision trace, which includes the original prompt, intermediate chain-of-thought, tool calls, tool responses, and the final action. Microsoft’s Responsible AI principles emphasize interpretability , suggesting that systems should be transparent enough for users to understand the rationale behind automated decisions.
Log design suggestion: include timestamps, model and prompt versions, retrieved context IDs, and permission checks for every tool invocation to create a full audit trail.
Multi-agent coordination and conflict resolution
When multiple agents operate in the same environment, they must negotiate goals, avoid conflicting actions, and share finite resources effectively. Researchers at Stanford HAI have explored how agents collaborate and conflict, noting that multi-agent systems require explicit role assignment and consensus protocols to prevent "deadlocks" or redundant work.
Practical patterns: use centralized arbitration for shared resources or implement token-based leasing and timeouts to ensure that no single agent stalls the entire system.
Tool hallucination and capability boundaries
Agents can occasionally “imagine” tools or misrepresent the capabilities of the APIs they have access to. You can prevent this by maintaining an explicit tool registry that lists each tool’s name, exact capabilities, accepted input schema, and failure modes.
Registry best practice: include automated schema checks and runtime capability probes so the agent can verify a tool’s status before attempting to rely on it for a critical task.
Agentic loop failure modes and recovery strategies
Agents can enter failure patterns such as infinite planning loops or cascading tool calls that consume excessive resources. Defend against these with architectural limits such as step-count caps and total timeouts. Utilizing a circuit breaker pattern to handle service failures can prevent an agent from repeatedly calling a failing API, thereby maintaining the overall health of the application.
Failure Mode | Safety Pattern |
|---|---|
Infinite Loop | Step-Count Caps & Timeouts |
API Downtime | Circuit Breaker Pattern |
Tool Hallucination | Input Schema Validation |
Resource Exhaustion | Token Usage Limits |
Example recoveries: if an agent hits a pre-defined step limit, the system should automatically save its state and escalate the task to a human reviewer rather than continuing indefinitely.
Context window management and token optimization
LLM context windows are finite, so long-running agents must manage which information to keep, which to compress, and when to fetch long-term memories. Optimize context length through strategies like summarization of past interactions and efficient retrieval via embedding indexes to prevent the agent from losing track of the goal.
Token optimization tactics:
1. Store dense embeddings for older context and retrieve only the top-k relevant items to save space.
2. Summarize multi-turn dialogs periodically and replace the detailed text with a high-level summary.
3. Prioritize user-specified context (e.g., specific privacy or compliance constraints) when trimming the history.
Reward modeling and preference alignment
Defining “good” behavior is more than just finishing a task; it includes safety, user satisfaction, and adherence to organizational values. Reward modeling—training a learned reward function from human judgments—is a standard technique for aligning agent choices with human preferences. This methodology is central to Reinforcement Learning from Human Feedback (RLHF) , which helps fine-tune models to be more helpful and less prone to harmful behavior.
Measurement: combine task success signals, human ratings, and operational metrics (e.g., error rates, time to resolution) into a composite score that guides iterative policy updates and improves agent performance over time.
Putting it together: a pragmatic checklist before deployment
Define roles and map permissions for every tool your agent might call using established [NIST RBAC standards](https://csrc.nist.gov/glossary/term/role-basedaccesscontrol).
Add a verification step for any action that changes state or uses sensitive data to ensure safety.
Log full decision traces and expose them to auditors to maintain high levels of transparency.
Enforce step/time limits and circuit breakers to manage failure modes effectively.
Use retrieval and embeddings to extend context instead of overstuffing tokens.
Define reward signals that capture safety and user satisfaction, not just task completion, to ensure long-term alignment.
What you should remember
AI agents combine planning, memory, and tools to act autonomously, but production readiness depends on careful design: fine-grained permissions, hallucination checks, observability, coordinated multi-agent protocols, failure-recovery safeguards, token-aware memory strategies, and well-defined reward models. Applying these patterns will help you move from a proof-of-concept agent to a reliable system that you—and regulators, auditors, and users—can trust.
Want support for Custom AI Agents?
See our custom AI agent offering and reach out on demand.
Custom AI Agent Development:format(webp))
:format(webp))
:format(webp))